import pandas as pd
import csv
import numpy as np
import networkx as nx
import matplotlib.pyplot as plt
def read_data(path):
# 读取CSV文件
df = pd.read_csv(path)
# 将每一列数据保存在列表中
column_data = []
for column in df.columns:
column_data.append(df[column].tolist())
return column_data
def get_fd(path):
data = read_data(path)
fd_from = [fd for fd in zip(data[1], data[2], data[3])]
fd_to = [fd for fd in zip(data[4], data[5], data[6])]
fd_from_uni = set(fd_from)
fd_to_uni = set(fd_to)
return fd_from, fd_to, fd_from_uni, fd_to_uni
def get_tb(path):
data = read_data(path)
td_from = [fd for fd in zip(data[1], data[2])]
td_to = [fd for fd in zip(data[4], data[5])]
td_from_uni = set(td_from)
td_to_uni = set(td_to)
tasks = data[0]
return td_from, td_to, td_from_uni, td_to_uni, tasks
def get_db(path):
data_all = read_data(path)
db_from, db_to = data_all[1], data_all[4]
tasks = data_all[0]
return db_from, db_to, tasks
def cons_db_dict_graph(path):
graph = {}
db_from, db_to, tasks = get_db(path)
db_all = db_from + db_to
for db in db_all:
if db not in graph:
graph[db] = []
for db_f, db_t in zip(db_from, db_to):
have_nodes = graph[db_f]
# 处理重复边,和自己指向自己的边
if db_t not in have_nodes and db_t != db_f:
graph[db_f].append(db_t)
return graph
def save_dict_graph(graph, filename):
with open(filename, 'w') as f:
for node, neighbors in graph.items():
neighbors_str = ".".join(map(str, neighbors))
# f.write(f"{str(node)}: {', '.join(str(neighbors))}\n")
f.write(f"{node}:{neighbors_str}\n")
print(f"Graph data saved to {filename}")
def load_graph(filename):
graph = {}
with open(filename, 'r') as f:
for line in f:
parts = line.strip().split(':')
node = int(parts[0])
neighbors = []
if len(parts) > 1 and parts[1]:
neighbors = list(map(int, parts[1].split('.')))
graph[node] = neighbors
return graph
def dfs(graph, start, path=[], paths=[]):
path = path + [start]
if start not in graph:
return paths
for node in graph[start]:
if node not in path:
paths = dfs(graph, node, path, paths)
paths.append(path) # 添加起点到当前节点的路径
return paths
from collections import deque
def bfs(graph, start, end):
queue = deque([(start, [start])]) # 初始化队列,起始节点和路径
while queue:
current, path = queue.popleft() # 从队列中取出当前节点和路径
if current == end: # 如果当前节点是终点,则返回路径
return path
for neighbor in graph.get(current, []): # 遍历当前节点的邻居节点
if neighbor not in path: # 如果邻居节点不在路径中
queue.append((neighbor, path + [neighbor])) # 将邻居节点和更新后的路径加入队列
return None # 如果没有找到路径,则返回 None
def cons_graph_deduplicate_edges(start, end, tasks):
deduplicate_edges = {}
start_uni = []
end_uni = []
for edge in zip(start, end):
if edge not in deduplicate_edges:
deduplicate_edges[edge] = 1
start_uni.append(edge[0])
end_uni.append(edge[1])
else:
deduplicate_edges[edge] += 1
print(len(start))
print(len(deduplicate_edges))
edges = pd.DataFrame()
edges["start"] = start_uni
edges["end"] = end_uni
G = nx.from_pandas_edgelist(edges, source="start", target="end")
return G
def print_all_paths(G, start):
# 使用广度优先搜索找到所有路径
for end in G.nodes():
if start == end:
continue
paths = list(nx.all_simple_paths(G, start, end))
if paths:
print(f"从节点 {start} 到节点 {end} 的路径:")
for path in paths:
print(path)
def db_graph_info():
path = './process_ret/re_code_all.csv'
db_from, db_to, tasks = get_db(path)
G = cons_graph_deduplicate_edges(db_from, db_to, tasks)
start_node = 1
print_all_paths(G, start_node)
# print(nx.degree(G))
# print(len(list(nx.connected_components(G))))
# print(list(nx.connected_components(G))[0])
# print(list(nx.connected_components(G))[1])
# print(list(nx.connected_components(G))[2])
# nx.draw(G, with_labels=True, edge_color='b', node_color='g', node_size=1000)
# plt.show()
def db_layer(fr, to, path='./process_ret/tb_nums_in_db_degree.csv'):
data = read_data(path)
db_code, out_d, in_d = data[0], data[2], data[3]
db_degree = {}
for info in zip(db_code, out_d, in_d):
db, od, id = info
db_degree[db] = [od, id]
# print(db_degree)
all_db = fr + to
all_db = list(set(all_db))
# print(len(all_db))
layer = []
layer_cur = []
index = 0
# 单独处理第一层
for db in all_db:
# 如果入度为0
if db_degree[db][1] == 0:
layer_cur.append(db)
all_db.remove(db)
layer.append(layer_cur)
layer_cur.clear()
layer_last = []
while len(all_db) > 0:
print(f"before process len of all_db : {len(all_db)}")
# 处理中间的层
# 如果入度不为0,出度不为0,并且入度来自上一层,
for db in all_db:
if db_degree[db][0] != 0 and db_degree[db][1] != 0: # 出度和入度不为0
for edge in zip(fr, to):
f, t = edge
if t == db and f in layer[index]: # 入度节点是来自于上一层
layer_cur.append(db)
all_db.remove(db)
break
if db_degree[db][0] == 0 and db_degree[db][1] != 0: # 出度为0
layer_last.append(db)
all_db.remove(db)
print(f"after process len of all_db : {len(all_db)}")
layer.append(layer_cur)
layer_cur.clear()
index += 1
layer.append(layer_last)
print(len(layer))
def cons_nx_graph(start_fd, end_fd, weights):
edges = pd.DataFrame()
edges["start"] = start_fd
edges["end"] = end_fd
edges["weights"] = weights
G = nx.from_pandas_edgelist(edges,source="start",target="end",edge_attr="weights")
return G
# 之前的入度出度文件此处不能用,因为没有去除重复表达以及自身到自身的度
def db_layer_handle_circle(fr, to, path='./process_ret/tb_nums_in_db_degree.csv'):
layers = []
layer_first = []
layer_last = []
all_db = list(set(fr + to))
print(f"all uni fr len:{len(fr)}, to len: {len(to)}")
print(f"all uni db len:{len(all_db)}")
# data = read_data(path)
# db_code, out_d, in_d = data[0], data[2], data[3]
# print(f"all uni db_code len:{len(db_code)}")
# 重新构造出度和入度的数据,排除重复表达的以及自身到自身的边
# 减少数据量,去掉重复的from - to
relations = [(f, t) for f, t in zip(fr, to)]
print(f"len of relation : {len(relations)}")
print(f"ele relation : {relations[0]}")
uni_relation = list(set(relations)) # 去除完全相同的边
uni_relation = [(f, t) for f, t in uni_relation if f != t] # 去除自身到自身的边
print(f"uni relations len : {len(uni_relation)}")
deduplicate_f = [f for f, _ in uni_relation]
deduplicate_t = [t for _, t in uni_relation]
dict_of_degree = {db: [deduplicate_f.count(db), deduplicate_t.count(db)] for db in all_db}
print(f"len of deduplicate_f and t : {len(deduplicate_f)} , {len(deduplicate_t)}")
print(f"deduplicate_f {deduplicate_f}")
print(f"deduplicate_t {deduplicate_t}")
print(f"dict degree : {dict_of_degree}")
print(f"len of dict degree : {len(dict_of_degree)}")
db_code, out_d, in_d = [], [], []
for k, v in dict_of_degree.items():
db_code.append(k)
out_d.append(v[0])
in_d.append(v[1])
print(f"db code : {db_code}")
print(f"db out_d : {out_d}")
print(f"db in_d : {in_d}")
# # 看看连通关系
# G = cons_nx_graph(deduplicate_f, deduplicate_t, deduplicate_f)
# print(f"lian tong",len(list(nx.connected_components(G))))
print(f"len of rest db all : {len(all_db)}")
# 找入度为0的结点,作为第一层
for info in zip(db_code, out_d, in_d):
db, od, id = info
if id == 0 and od != 0:
layer_first.append(db)
all_db.remove(db)
if od == 0 and id == 0:
layer_first.append(db)
all_db.remove(db)
print(f"len of first layer : {len(layer_first)}")
# 找出度为0的结点,作为最后层
for info in zip(db_code, out_d, in_d):
db, od, id = info
if od == 0 and id != 0 :
layer_last.append(db)
all_db.remove(db)
# print(f"len of first layer: {len(layer_first)}")
# print(f"ele of first layer: {layer_first}")
layers.append(layer_first)
print(f"len of last layer : {len(layer_last)}\n")
# 验证
# uni_re = {}
# for re in zip(fr,to):
# if re not in uni_re:
# uni_re[re] = 1
# print(f"uni dict relation len : {len(uni_re)}")
# 找中间层
index = 0
layer_cur = []
print(f"len of rest db all : {len(all_db)}")
while len(all_db) > 0:
# step1,寻找直接来自于上一层的结点,全部找完之后进行下一步
# for db in all_db:
# for re in uni_relation:
# f, t = re
# if db == t and f in layers[index] and t not in layer_cur: # 某条f到t的关系满足起点f在上一层,终点t是当前的结点
# # print(f"from : {f}, to : {t}")
# # print(f"process cur db : {db}")
# tp = db
# layer_cur.append(tp)
# all_db.remove(db)
# for re in uni_relation:
# f, t = re
# if f in layers[index] and t not in layer_cur and t in all_db:
# # print(f"from : {f}, to : {t}")
# layer_cur.append(t)
# all_db.remove(t)
for db in layers[index]:
for re in uni_relation:
f, t = re
if db == f and t in all_db:
layer_cur.append(t)
all_db.remove(t)
# print(f"cur layer len : {len(layer_cur)} , db : {layer_cur}")
# step2,寻找指向本层的结点,因为要找完,不确定有没有,并且顺序也不知道
flag = 1
# for re in uni_relation:
# f, t = re
# if t in layer_cur and f in all_db: # 存在一个边指向本层结点,并且起点是没使用过的,表明可以开始寻找
# flag = 1
while flag != 0:
flag = 0
for re in uni_relation:
f, t = re
if t in layer_cur and f in all_db: # 存在一个边指向本层结点,并且起点是没使用过的,表明可以开始寻找
flag = 1
layer_cur.append(f)
all_db.remove(f)
layers.append(layer_cur)
print(f"len of cur layer : {len(layer_cur)}")
print(f"len of rest db all : {len(all_db)}")
print("\n")
index += 1
layer_cur.clear()
# print(f"index : {index}")
# print(f"layer all len: {len(layers)}")
path = './process_ret/re_code_all.csv'
data = read_data(path)
fr, to = data[1], data[4]
db_layer_handle_circle(fr, to)
# db_graph_info()
# G = cons_db_dict_graph(path)
# print(G)
# save_dict_graph(G, './process_ret/db_graph.txt')
# start = 1
# end = 238
# print(bfs(G,start,end))
# PATH = dfs(G, start)
# print(PATH)
# g = load_graph('./process_ret/db_graph.txt')
# print(g)
code4job
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.mfbz.cn/a/573302.html
如若内容造成侵权/违法违规/事实不符,请联系我们进行投诉反馈qq邮箱809451989@qq.com,一经查实,立即删除!相关文章
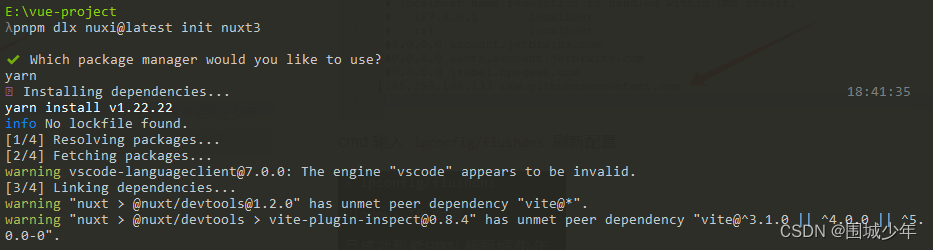
nuxt3 无法创建项目问题
Error: Failed to download template from registry: Failed to download https://raw.githubusercontent.com/nuxt/starter/templates/templates/v3.json: TypeError: fetch failed
错误信息 解决方案
进入windows系统修改hosts文件
C:\Windows\System32\drivers\etc增加以…
IDEA中Vue开发环境搭建
1. IDEA安装Vue.js 文件>设置>插件>搜索Vue.js并安装。
2. 安装Node.js 官网地址:https://nodejs.org 安装包下载地址:https://nodejs.org/en/download 下载并安装,安装时,勾选添加系统变量选项。
# 如果正确安装…
如何批量跟踪京东物流信息
随着电商行业的快速发展,快递业务日益繁忙,无论是商家还是消费者,都需要一种高效、便捷的快递查询工具。快递批量查询高手软件应运而生,以其强大的功能和便捷的操作体验,赢得了广大电商、微商精英们的青睐。
快递批量…

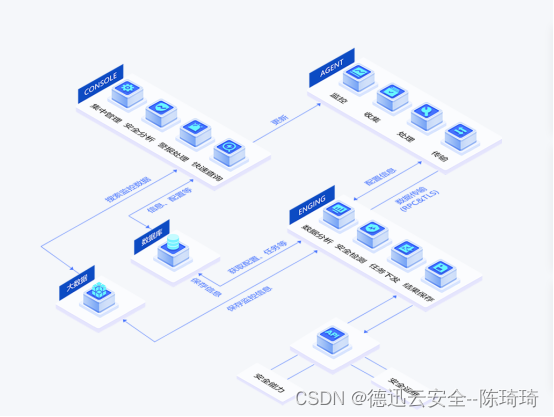
通用计算平台与医用计算平台的差异
1.通用计算平台参考信息
《医疗器械软件注册审查指导原则(2022年修订版)(2022年第9号)》中关于“通用计算平台”有说参考《IMDRF/SaMD WG/N10 FINAL: 2013》
2.IMDRF/SaMD WG/N10 FINAL: 2013中关于通用计算平台的说明 3.通用计…

YOLOv8常见水果识别检测系统(yolov8模型,从图像、视频和摄像头三种路径识别检测)
1.效果视频(常见水果识别(yolov8模型,从图像、视频和摄像头三种路径识别检测)_哔哩哔哩_bilibili)
资源包含可视化的水果识别检测系统,可识别图片和视频当中出现的六类常见的水果,包括…

git lab 2.7版本修改密码命令
1.gitlab-rails console -e production
Ruby: ruby 2.7.5p203 (2021-11-24 revision f69aeb8314) [x86_64-linux] GitLab: 14.9.0-jh (51fb4a823f6) EE GitLab Shell: 13.24.0 PostgreSQL: 12.7
2根据用户名修改密码 user User.find_by(username: ‘username’) # 替换’use…

2024年航空航天与工业技术国际学术会议(IACAIT 2024)
2024年航空航天与工业技术国际学术会议(IACAIT 2024) 2024 International Conference on Aerospace and Industrial Technology
一、【会议简介】 2024年航空航天与工业技术国际学术会议,将汇集全球顶尖专家,探讨前沿技术。 这次会议主题为“航空航天与…
PMP®考试的形式、题型、考试内容和趋势
PMP考试形式:
国内的PMP考试是由中国国际人才交流基金会和PMI共同组织举办,统一采取的都是线下笔试。一年考4次,今年的考试安排在3月、6月、8月、11月。3月10日的PMP考试已结束,接下来是6月份的考试,考试时间预计在6月…
2024年了,还有必要搭建企业网站吗?
现在企业的营销手段五花八门。当下火爆的短视频直播平台展现出的裂变效应也取得不错的成绩,这不禁让很多企业舍弃做网站的念头,投入自媒体账号。那么,2024年了,还有必要搭建企业网站吗?
我们分两种企业来看࿱…

利用弹性云主机部署高效数据库系统
在当今云计算的时代,弹性云主机(EC2)为我们提供了前所未有的灵活性和可扩展性,使得在云端部署高效的数据库系统成为可能。本文将从选择适当的云服务配置、优化数据库设置、建立完备的数据备份与恢复策略,以及加强数据库…
LeetCode-219. 存在重复元素 II
题目描述
给你一个整数数组 nums 和一个整数 k ,判断数组中是否存在两个 不同的索引 i 和 j ,满足 nums[i] nums[j] 且 abs(i - j) < k 。如果存在,返回 true ;否则,返回 false 。 示例 1:
输入&…
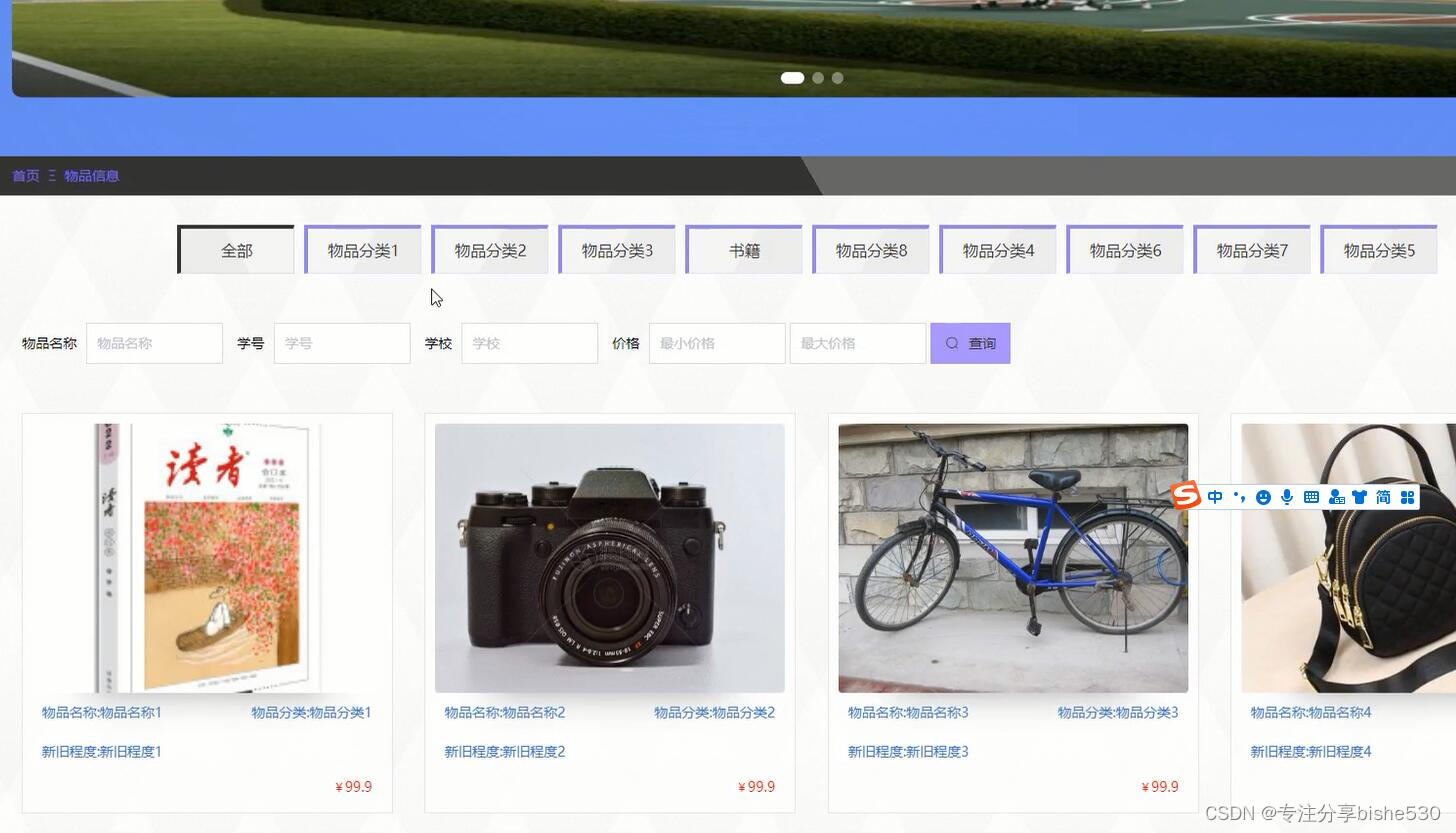
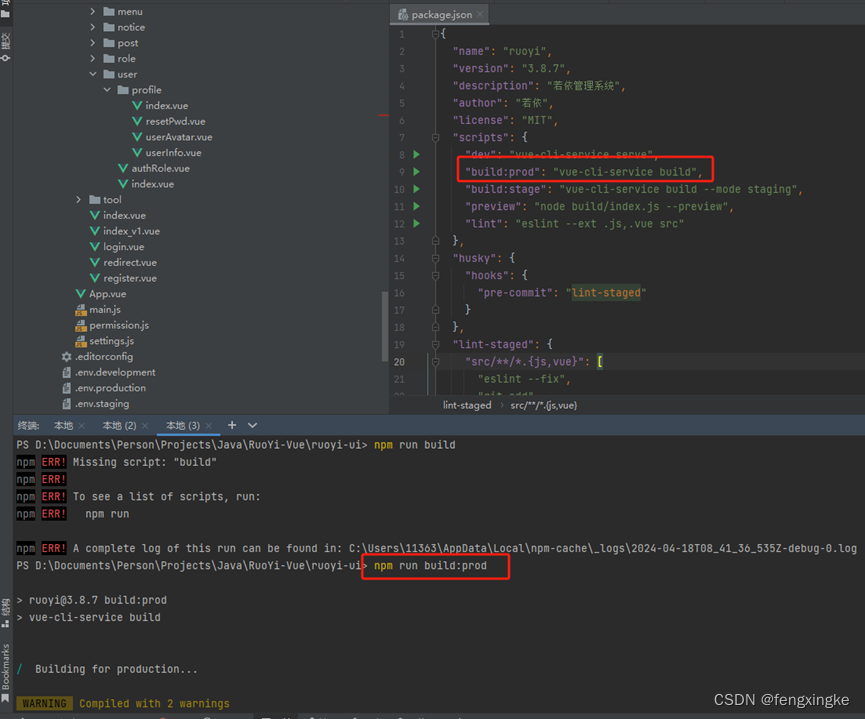
springboot+vue学习用品商店商城系统java毕业设计ucozu
该系统利用java语言、MySQL数据库,springboot框架,结合目前流行的 B/S架构,将互动式学习用品网上商城平台的各个方面都集中到数据库中,以便于用户的需要。该系统在确保系统稳定的前提下,能够实现多功能模块的设计和应用…

天人、人间、二神之间的宗教战争
文本:创世记 2-3、马太福音 23-24、启示录 12-13 天人、地球人和两位神之间的宗教战争是什么样的? 属天的(天体)是神(创世记6),属地的(地上的人)是肉身。有两个主要的…
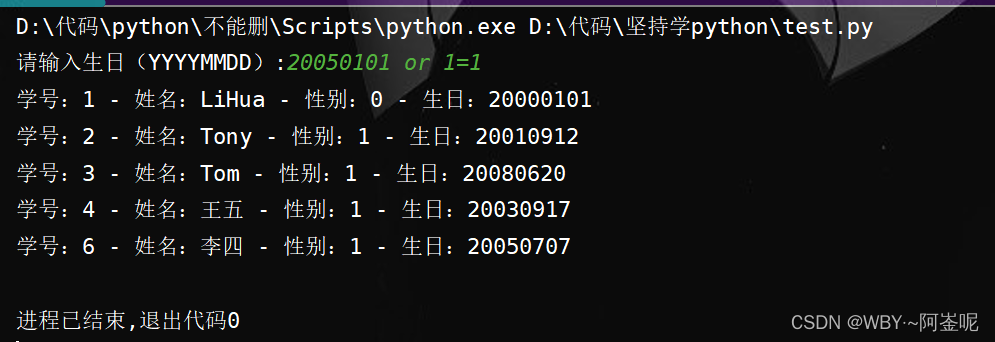
学python的第十九天
网络通信和访问数据库
1.1 基本的网络知识
TCP/IP IP是低级的路由协议,它将数据拆分在许多小的数据包中,并通过网络将他们发送到某一特定地址,但无法保证所有包都抵达目的地,也不能保证包按顺序抵达 TCP(传输控制协议…

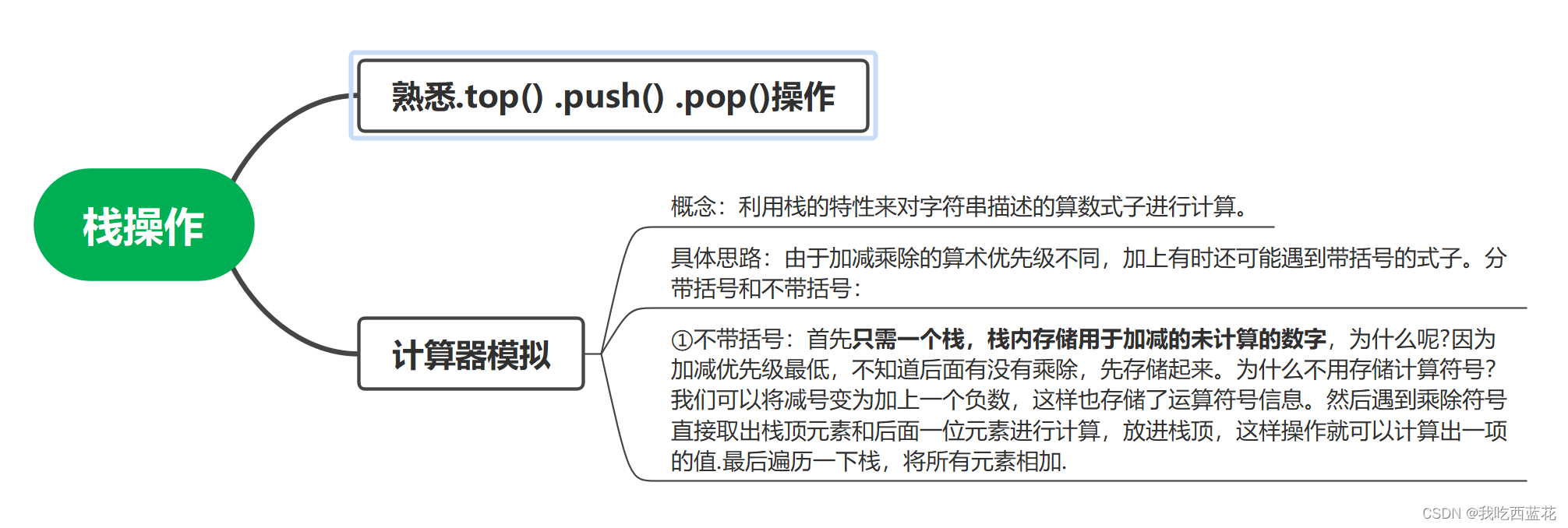
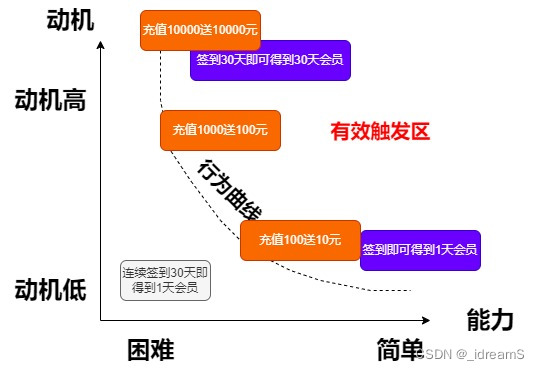
2.搭建增长模型-福格行为模型
福格行为模型 Bmat
B为行动
m是动机
a是能力
t是触发 mat三者是同时出现的 比如连续签到30天,才送1天会员,这明摆着欺负人,用户难有积极性 但是签到即可或者会员1天,连续30天送30天,这样用户每天都会积极的来签到&…
学习交流论坛-测试报告
🌟 欢迎来到 我的博客! 🌈 💡 探索未知, 分享知识 !💫 本文目录 1. 项目描述2. 测试计划2.1 功能测试2.1.1 测试环境2.1.2 编写测试用例2.1.3 部分手工功能测试 2.2 自动化测试2.2.1 注册页面2.2.2 登录页面2.2.3 博客…

链表(2) ---- 完整版
目录 一 . 前言二 . 头文件声明三 . 代码思绪1. 查找函数的实现2. 在指定位置之前插入3. 在指定位置之后插入4. 删除指定位置的结点5. 删除指定位置之后的结点6. 销毁链表 四 . 完整代码五 . 总结 正文开始
一 . 前言 补充说明: 1、链式机构在逻辑上是连续的&#…

最新文章
- 一个完全免费、私有且本地运行的搜索聚合器-FreeAskInternet
- 如何优雅的分析你的微信朋友圈和聊天记录
- 深度解析 Spring 源码:探寻Bean的生命周期
- [论文阅读] 测试时间自适应TTA
- 【开源物联网平台】window环境下搭建调试监控设备环境
- 吴恩达2022机器学习专项课程(一)8.2 解决过拟合
- python学习之词云图片生成
- Tcp自连接
- 使用Python实现批量删除MYSQL数据库的全部外键
- 【网络】gateway 可以提供的一些功能之一 “ 提供web静态资源服务 ”
- HttpURLConnection 接收长字符串时出现中文乱码出现问号��
- 深度学习之视觉特征提取器——VGG系列
- 自然语言处理基础
- Java将文件目录转成树结构
- Java实现裁剪PDF
- 如何使用 ArcGIS Pro 查找小区最近的地铁站
- virtualbox kafka nat + host-only集群 + windows 外网 多网卡
- 初识ChatGPT
- 2000-2020年县域创业活跃度数据
- 分割回文串(力扣131)
- python数据可视化:显示两个变量间的关系散点图scatterplot()
- microk8s的registry私有镜像库
- Java面试问题及答案
- Java中的可变参数
- ⛳ Java多线程 一,线程基础
- SQLiteC/C++接口详细介绍之sqlite3类(十)
- LeetCode解法汇总2208. 将数组和减半的最少操作次数
- 软考-高级-系统架构设计师教程(清华第2版)【第13章 层次式架构设计理论与实践(P466~495)-思维导图】
- # Maven Bom 的使用
- # Panda3d 碰撞检测系统介绍